Boas Práticas
The basic steps as we stated them are step one is you have to realize that your data is the result from an experiment. So you have to describe the experiment which generated the data and then with that you can also start describing the kind of the causal question you have. - Mark van der Laan
Toda inferência causal sustenta-se em dois pilares fundamentais: premissas e resultados.
As premissas devem ser declaradas explicitamente e rigorosamente respeitadas. Caso haja suspeita de violação ou impossibilidade de validação completa de alguma delas, é preferível que essa limitação seja apontada e elucidada no estudo, em vez de ofuscada. Um estudo honesto, que respeita tanto o método científico quanto o leitor, mantém seu valor mesmo com limitações declaradas.
Resultados e hipóteses exigem seriedade e cronologia. As hipóteses devem ser formuladas antes do estudo (pré-registro), e não ajustadas a posteriori para se adequarem aos dados observados. Modelar resultados baseando-se em hipóteses criadas após a análise é uma prática problemática (HARKing), pois aumenta o risco de detectar padrões espúrios e induzir a tomadas de decisão equivocadas.
Portanto, um escopo de boas práticas deve focar na leitura crítica dos resultados, visando responder perguntas de causa e efeito que impactam a unidade de estudo. Para auxiliar, o artigo abaixo é uma referência que estabelece um fluxo de trabalho e recomendações de validação utilizando modelos de Machine Learning (ML) para prever resultados de tratamentos com segurança:
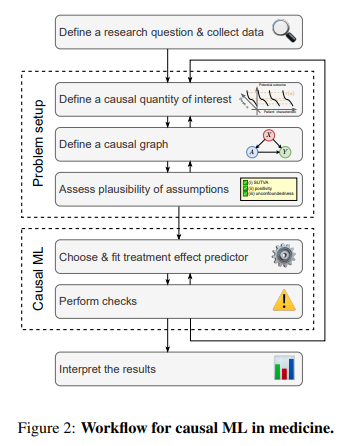
Causal machine learning for predicting treatment outcomes
Além disso, a estruturação do processo é de suma vital. O trabalho A Causal Roadmap, por exemplo, busca rigor metodológico. Ele estabelece um roteiro de sete etapas para gerar evidências de alta qualidade em dados do mundo real (RWE), guiando desde a formulação da pergunta até a estimativa do efeito:
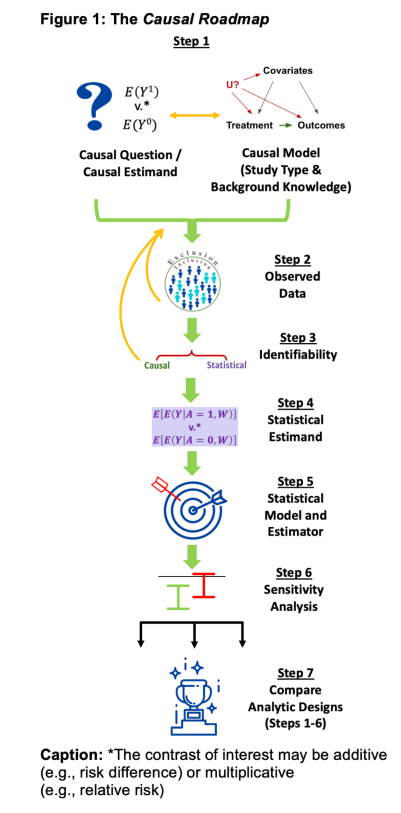
A Causal Roadmap for Generating High-Quality Real-World Evidence
É importante pontuar que no artigo esclarece a importância do pesquisador em utilizar frameworks rigorosos, citando como exemplo Target Trial Emulation (TTE), que exige a especificação explícita de quatro componentes:
- População: Quem seria elegível para o ensaio?
- Estratégias de Tratamento: Quais as intervenções exatas a comparar?
- Atribuição e Seguimento: Como e por quanto tempo os grupos são monitorizados?
- Outcome: Qual o outcome definido à priori?
Para facilitar a identificação da abordagem adequada, deixei um infográfico dinâmico para me ajudar a fixar ao tema, mas utilize com ressalvas, acredito em suma ser limitado e potencialmente errôneo. Se você utiliza ferramentas de GenAI, há o PyWhyLLM como assistente para exploração, ou o Causal LLM Agent citados anteriormente em 13. GenAI e Causal Reasoning.
Equívocos
Embora possamos utilizar algoritmos preditivos em análises causais, as abordagens divergem em objetivos e interpretação. Modelos causais exigem maior maturidade teórica para identificar o efeito de uma intervenção, indo além da correlação.
Abaixo, listo equívocos que podem surgir durante a construção de um modelo causal:
1. Assumir causalidade em dados observacionais sem critério
Observações empíricas que mostram associação entre duas variáveis não permitem, por si só, concluir causalidade. A associação pode ser fruto de confusão, causalidade reversa ou mera coincidência.
- Exemplo: As vendas de sorvete e o número de afogamentos aumentam simultaneamente; a temperatura (variável omitida) é a causa comum de ambos.
- Como evitar: Sempre observe a construção do DAG, procure fontes de variação plausivelmente exógenas, use desenho experimental quando possível, e declare explicitamente as premissas necessárias para qualquer interpretação causal.
2. Acreditar que a Randomização resolve todos os problemas
Ensaios aleatorizados reduzem vieses de seleção na atribuição do tratamento, mas não* garantem validade externa automática, ausência de vieses de medição, ou ausência de não‑compliance, perdas de seguimento e efeitos indiretos.
- Exemplo: Um experimento onde muitos participantes do grupo de tratamento desistem (attrition) gera estimativas enviesadas.
- Como evitar: Monitore a adesão e perdas de seguimento; considere estimadores como Variáveis Instrumentais para lidar com a não-conformidade.
3. Controlar o máximo de variáveis possível
Diferente do mundo preditivo, onde "mais dados costumam ser melhor", na causalidade, incluir certas variáveis pode introduzir viés. Controlar mediadores ou colisores pode distorcer o efeito real.
- Ponto Chave: Um alto
ou poder preditivo não implica poder causal. Incluir um colisor pode gerar uma correlação espúria onde não existe causalidade. - Como evitar: Utilize o critério de Backdoor no seu DAG para decidir quais variáveis devem (e quais não podem) ser controladas.
4. Substituir o pensamento causal por modelos complexos
Modelos de Machine Learning altamente flexíveis podem prever o outcome com precisão, mas não explicam o que aconteceria sob uma intervenção. A complexidade do algoritmo não valida a suposição causal.
- Como evitar: Combine ML com frameworks causais (como Double Machine Learning), documente as premissas e realize análises de sensibilidade.
5. Ignorar a Heterogeneidade do Efeito
Assumir que o efeito causal é o mesmo para todos os indivíduos (homogeneidade) pode mascarar resultados importantes.
- Exemplo: Um desconto que aumenta as vendas para jovens, mas reduz o valor da marca para clientes premium.
- Como evitar: Estime efeitos heterogêneos (CATE - Conditional Average Treatment Effect) e discuta os limites da generalização dos resultados.
6. Tratar o P-valor como prova de causalidade
A significância estatística quantifica apenas a incerteza amostral sob um modelo específico; ela não valida suas suposições causais. Um efeito estatisticamente significativo (
- O Trade-off: Isso está ligado ao equilíbrio entre Viés e Variância, que comentei anteriormente. Um modelo pode ter variância baixa (estimativas precisas/p-valor baixo), mas estar altamente enviesado por não considerar a estrutura causal correta.
- Magnitude vs. Significância: Um tamanho de efeito grande ou um alto nível de significância não garantem benefícios práticos ou validade causal. Em grandes bases de dados (Big Data), quase qualquer correlação irrelevante pode se tornar "estatisticamente significativa", mesmo sem qualquer sentido causal. Uma variável com alto poder causal pode apresentar um
-valor alto (não significante) se a amostra for pequena ou a variância for elevada. Não confunda precisão estatística com relevância causal.
Como evitar:
- Foque na magnitude do efeito e nos Intervalos de Confiança, que mostram a incerteza de forma mais transparente.
- Priorize a robustez do desenho do estudo em vez da busca por
-valores baixos. - Combine a evidência estatística com argumentos teóricos e testes de sensibilidade.